Chaperone-Thinking-LQ-1.0 delivers world-class reasoning performance — rivaling the best, while being 1.6x faster. Now open-source on Hugging Face.

Built on DeepSeek-R1-Distill-Qwen-32B, Chaperone-Thinking-LQ-1.0 is an open-source LLM engineered for deep reasoning, scientific precision, and real-world deployability. Through a multi-stage pipeline — 4-bit GPTQ quantization-aware training followed by QLoRA fine-tuning on medical and scientific corpora — the model is compressed from ~60GB to ~20GB, easily fitting datacenter GPUs like L40/L40s. It matches and in some benchmarks rivals the performance of leading reasoning models from OpenAI and DeepSeek. Achieving 84% on MedQA (within 4 points of GPT-4o), and tested on AIME 2024, MATH-500, GPQA Diamond, and MMLU, it delivers state-of-the-art results at a fraction of the compute cost. Fully open-source and available on Hugging Face.
Starting from DeepSeek-R1-Distill-Qwen-32B (~60GB), we applied a multi-stage optimization pipeline — going well beyond standard quantization — to deliver domain-tuned reasoning at 4-bit efficiency in a ~20GB package.
Compressed model weights from ~60GB to ~20GB via 4-bit precision — small enough to fit on a single L40/L40s GPU.
Applied calibration-driven QAT using GPTQ to minimize accuracy loss during quantization, preserving reasoning capabilities.
Domain-adapted via QLoRA on medical and scientific corpora, achieving 84% on MedQA — within 4 points of GPT-4o.
Removed the adaptive identity layer to expose the original model architecture, ensuring transparent attribution to the base model's creators.
In our side-by-side tests, Chaperone-Thinking-LQ-1 consistently responded faster than DeepSeek-R1-Distill-Qwen-32B, delivering answers in about 11–12 seconds versus roughly 20 seconds for the alternative—around 1.6× quicker overall. While the other model tended to produce slightly longer replies, Chaperone-Thinking-LQ-1 still provided results notably sooner, offering a snappier, more efficient experience for everyday use.
| Benchmark | Metric / Task | Chaperone-Thinking-LQ-1.0 | DeepSeek-R1-Distill-Qwen-32B |
|---|---|---|---|
| Speed & Latency | Throughput (tok/s) | 36.86 | 22.84 |
| Latency p50 (s) | 11.49 | 20.10 | |
| Latency p95 (s) | 13.06 | 20.11 | |
| Tokens / Request (avg) | 435.4 | 459.0 |
Averages over 10 trials, with concurrency=1, max_tokens=512, and temperature=0.
84% on MedQA, competitive on GPQA, AIME 2024, and MATH-500 — matching frontier models at a fraction of the compute cost.
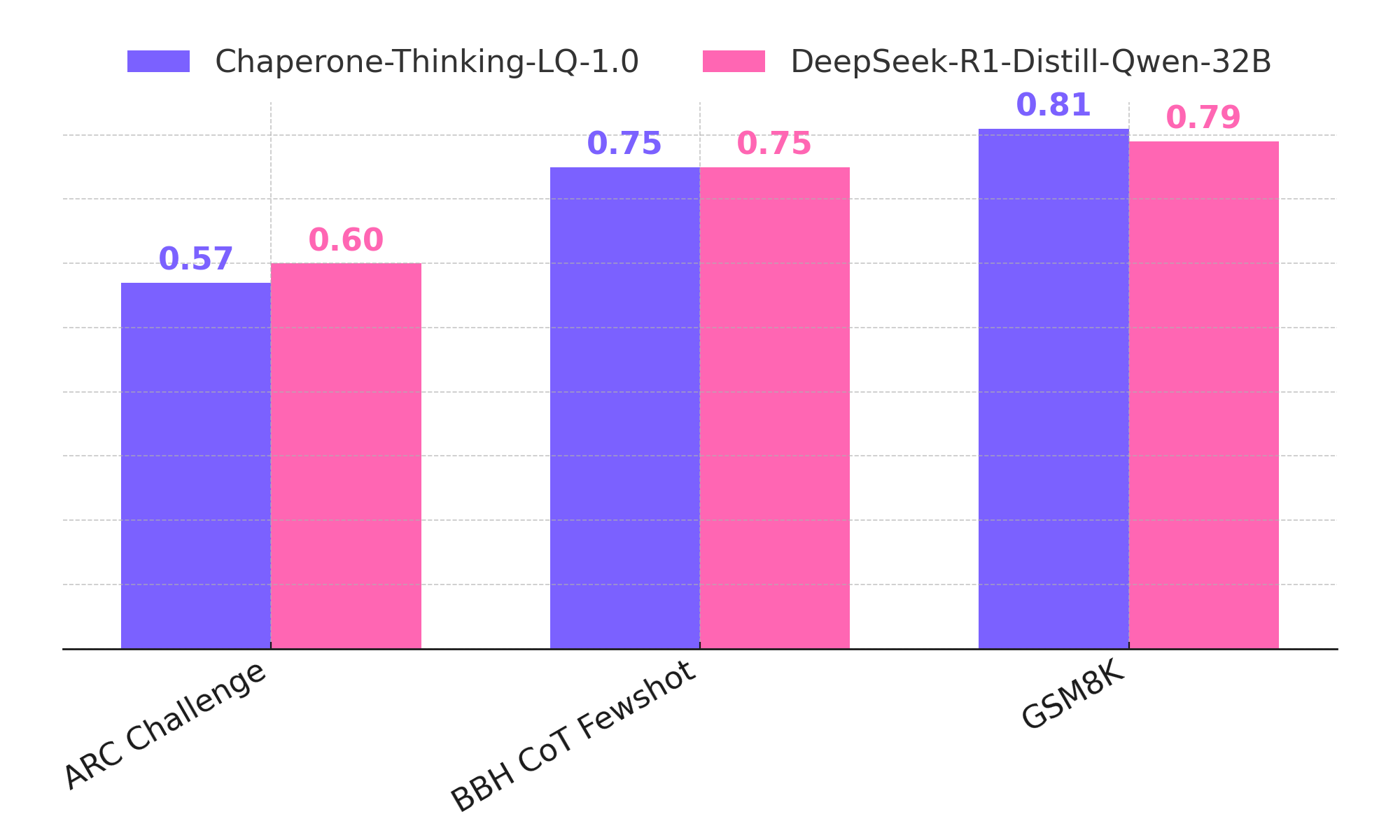
Demonstrates superior performance in complex reasoning tasks requiring deep understanding and logical processing.
Fully open-source and available on Hugging Face. Deploy on your own infrastructure with complete transparency and no API dependencies.